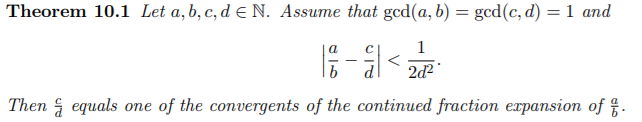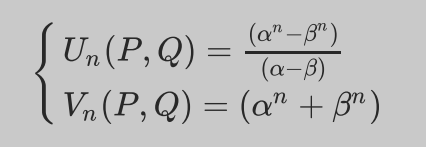defFactorize(n, e, d): g = 2 whileTrue: k = e * d - 1 whilenot k & 1: k //= 2 p = int(gcd(pow(g, k, n) - 1, n)) % n if p > 1: return (p, n // p) g = int(next_prime(g))
if __name__ == "__main__": n = e = d = print(Factorize(n, e, d))
from Crypto.Util.number import long_to_bytes import gmpy2
defdecrypt(e, dp, n): _ = dp * e - 1 for i in range(1, e): ifnot _ % i: p = _ // i + 1 ifnot n % p: q = n // p phi = (p - 1) * (q - 1) d = int(gmpy2.invert(e, phi)) return d
if __name__ == "__main__": e = int(input("e = ")) dp = int(input("dp = ")) n = int(input("n = ")) c = int(input("c = ")) d = decrypt(e, dp, n) print(long_to_bytes(pow(c, d, n)))
import gmpy2 from Crypto.Util.number import long_to_bytes
defrational_to_quotients(x, y): a = x // y quotients = [a] while a * y != x: x, y = y, x - a * y a = x // y quotients.append(a) return quotients
defconvergents_from_quotients(quotients): convergents = [(quotients[0], 1)] for i in range(2, len(quotients) + 1): quotients_partion = quotients[0:i] denom = quotients_partion[-1] # 分母 num = 1 for _ in range(-2, -len(quotients_partion), -1): num, denom = denom, quotients_partion[_] * denom + num num += denom * quotients_partion[0] convergents.append((num, denom)) return convergents
defWienerAttack(e, n): quotients = rational_to_quotients(e, n) convergents = convergents_from_quotients(quotients) for (k, d) in convergents: if k andnot (e * d - 1) % k: phi = (e * d - 1) // k # check if (x^2 - coef * x + n = 0) has integer roots coef = n - phi + 1 delta = coef * coef - 4 * n if delta > 0and gmpy2.iroot(delta, 2)[1] == True: print('d = ' + str(d)) return d
if __name__ == "__main__": e = int(input("e = ")) n = int(input("n = ")) c = int(input("c = ")) d = WienerAttack(e, n) plaintext = long_to_bytes(pow(c, d, n)) print(plaintext)
defpartial_p(p0, kbits, n): PR.<x> = PolynomialRing(Zmod(n)) nbits = n.nbits() f = 2^kbits*x + p0 f = f.monic() roots = f.small_roots(X=2^(nbits//2-kbits), beta=0.4) # find root < 2^(nbits//2-kbits) with factor >= n^0.4 if roots: x0 = roots[0] p = gcd(2^kbits*x0 + p0, n) return ZZ(p)
deffind_p(d0, kbits, e, n): X = var('X') for k in range(1, e+1): results = solve_mod([e*d0*X - k*X*(n-X+1) + k*n == X], 2^kbits) for x in results: p0 = ZZ(x[0]) p = partial_p(p0, kbits, n) if p and p != 1: return p
if __name__ == '__main__': n = e = c = d0 = beta = 0.5 nbits = n.nbits() kbits = d0.nbits() print("lower %d bits (of %d bits) is given" % (kbits, nbits))
p = int(find_p(d0, kbits, e, n)) print("found p: %d" % p) q = n//int(p) print("d:", inverse_mod(e, (p-1)*(q-1)))
""" Setting debug to true will display more informations about the lattice, the bounds, the vectors... """ debug = True
""" Setting strict to true will stop the algorithm (and return (-1, -1)) if we don't have a correct upperbound on the determinant. Note that this doesn't necesseraly mean that no solutions will be found since the theoretical upperbound is usualy far away from actual results. That is why you should probably use `strict = False` """ strict = False
""" This is experimental, but has provided remarkable results so far. It tries to reduce the lattice as much as it can while keeping its efficiency. I see no reason not to use this option, but if things don't work, you should try disabling it """ helpful_only = True dimension_min = 7# stop removing if lattice reaches that dimension
# display stats on helpful vectors defhelpful_vectors(BB, modulus): nothelpful = 0 for ii in range(BB.dimensions()[0]): if BB[ii,ii] >= modulus: nothelpful += 1
print(nothelpful, "/", BB.dimensions()[0], " vectors are not helpful")
# display matrix picture with 0 and X defmatrix_overview(BB, bound): for ii in range(BB.dimensions()[0]): a = ('%02d ' % ii) for jj in range(BB.dimensions()[1]): a += '0'if BB[ii,jj] == 0else'X' if BB.dimensions()[0] < 60: a += ' ' if BB[ii, ii] >= bound: a += '~' print(a)
# tries to remove unhelpful vectors # we start at current = n-1 (last vector) defremove_unhelpful(BB, monomials, bound, current): # end of our recursive function if current == -1or BB.dimensions()[0] <= dimension_min: return BB
# we start by checking from the end for ii in range(current, -1, -1): # if it is unhelpful: if BB[ii, ii] >= bound: affected_vectors = 0 affected_vector_index = 0 # let's check if it affects other vectors for jj in range(ii + 1, BB.dimensions()[0]): # if another vector is affected: # we increase the count if BB[jj, ii] != 0: affected_vectors += 1 affected_vector_index = jj
# level:0 # if no other vectors end up affected # we remove it if affected_vectors == 0: print("* removing unhelpful vector", ii) BB = BB.delete_columns([ii]) BB = BB.delete_rows([ii]) monomials.pop(ii) BB = remove_unhelpful(BB, monomials, bound, ii-1) return BB
# level:1 # if just one was affected we check # if it is affecting someone else elif affected_vectors == 1: affected_deeper = True for kk in range(affected_vector_index + 1, BB.dimensions()[0]): # if it is affecting even one vector # we give up on this one if BB[kk, affected_vector_index] != 0: affected_deeper = False # remove both it if no other vector was affected and # this helpful vector is not helpful enough # compared to our unhelpful one if affected_deeper and abs(bound - BB[affected_vector_index, affected_vector_index]) < abs(bound - BB[ii, ii]): print("* removing unhelpful vectors", ii, "and", affected_vector_index) BB = BB.delete_columns([affected_vector_index, ii]) BB = BB.delete_rows([affected_vector_index, ii]) monomials.pop(affected_vector_index) monomials.pop(ii) BB = remove_unhelpful(BB, monomials, bound, ii-1) return BB # nothing happened return BB
""" Returns: * 0,0 if it fails * -1,-1 if `strict=true`, and determinant doesn't bound * x0,y0 the solutions of `pol` """ defboneh_durfee(pol, modulus, mm, tt, XX, YY): """ Boneh and Durfee revisited by Herrmann and May finds a solution if: * d < N^delta * |x| < e^delta * |y| < e^0.5 whenever delta < 1 - sqrt(2)/2 ~ 0.292 """
# x-shifts gg = [] for kk in range(mm + 1): for ii in range(mm - kk + 1): xshift = x^ii * modulus^(mm - kk) * polZ(u, x, y)^kk gg.append(xshift) gg.sort()
# x-shifts list of monomials monomials = [] for polynomial in gg: for monomial in polynomial.monomials(): if monomial notin monomials: monomials.append(monomial) monomials.sort() # y-shifts (selected by Herrman and May) for jj in range(1, tt + 1): for kk in range(floor(mm/tt) * jj, mm + 1): yshift = y^jj * polZ(u, x, y)^kk * modulus^(mm - kk) yshift = Q(yshift).lift() gg.append(yshift) # substitution # y-shifts list of monomials for jj in range(1, tt + 1): for kk in range(floor(mm/tt) * jj, mm + 1): monomials.append(u^kk * y^jj)
# construct lattice B nn = len(monomials) BB = Matrix(ZZ, nn) for ii in range(nn): BB[ii, 0] = gg[ii](0, 0, 0) for jj in range(1, ii + 1): if monomials[jj] in gg[ii].monomials(): BB[ii, jj] = gg[ii].monomial_coefficient(monomials[jj]) * monomials[jj](UU,XX,YY)
# Prototype to reduce the lattice if helpful_only: # automatically remove BB = remove_unhelpful(BB, monomials, modulus^mm, nn-1) # reset dimension nn = BB.dimensions()[0] if nn == 0: print("failure") return0,0
# check if vectors are helpful if debug: helpful_vectors(BB, modulus^mm) # check if determinant is correctly bounded det = BB.det() bound = modulus^(mm*nn) if det >= bound: print("We do not have det < bound. Solutions might not be found.") print("Try with highers m and t.") if debug: diff = (log(det) - log(bound)) / log(2) print("size det(L) - size e^(m*n) = ", floor(diff)) if strict: return-1, -1 else: print("det(L) < e^(m*n) (good! If a solution exists < N^delta, it will be found)")
# display the lattice basis if debug: matrix_overview(BB, modulus^mm)
# LLL if debug: print("optimizing basis of the lattice via LLL, this can take a long time")
BB = BB.LLL()
if debug: print("LLL is done!")
# transform vector i & j -> polynomials 1 & 2 if debug: print("looking for independent vectors in the lattice") found_polynomials = False for pol1_idx in range(nn - 1): for pol2_idx in range(pol1_idx + 1, nn): # for i and j, create the two polynomials PR.<w,z> = PolynomialRing(ZZ) pol1 = pol2 = 0 for jj in range(nn): pol1 += monomials[jj](w*z+1,w,z) * BB[pol1_idx, jj] / monomials[jj](UU,XX,YY) pol2 += monomials[jj](w*z+1,w,z) * BB[pol2_idx, jj] / monomials[jj](UU,XX,YY)
# are these good polynomials? if rr.is_zero() or rr.monomials() == [1]: continue else: print("found them, using vectors", pol1_idx, "and", pol2_idx) found_polynomials = True break if found_polynomials: break
ifnot found_polynomials: print("no independant vectors could be found. This should very rarely happen...") return0, 0 rr = rr(q, q)
# solutions soly = rr.roots()
if len(soly) == 0: print("Your prediction (delta) is too small") return0, 0
soly = soly[0][0] ss = pol1(q, soly) solx = ss.roots()[0][0]
# return solx, soly
defexample(): ############################################ # How To Use This Script ##########################################
# # The problem to solve (edit the following values) #
# the modulus N = 0xbadd260d14ea665b62e7d2e634f20a6382ac369cd44017305b69cf3a2694667ee651acded7085e0757d169b090f29f3f86fec255746674ffa8a6a3e1c9e1861003eb39f82cf74d84cc18e345f60865f998b33fc182a1a4ffa71f5ae48a1b5cb4c5f154b0997dc9b001e441815ce59c6c825f064fdca678858758dc2cebbc4d27 # the public exponent e = 0x11722b54dd6f3ad9ce81da6f6ecb0acaf2cbc3885841d08b32abc0672d1a7293f9856db8f9407dc05f6f373a2d9246752a7cc7b1b6923f1827adfaeefc811e6e5989cce9f00897cfc1fc57987cce4862b5343bc8e91ddf2bd9e23aea9316a69f28f407cfe324d546a7dde13eb0bd052f694aefe8ec0f5298800277dbab4a33bb c = 0xe3505f41ec936cf6bd8ae344bfec85746dc7d87a5943b3a7136482dd7b980f68f52c887585d1c7ca099310c4da2f70d4d5345d3641428797030177da6cc0d41e7b28d0abce694157c611697df8d0add3d900c00f778ac3428f341f47ecc4d868c6c5de0724b0c3403296d84f26736aa66f7905d498fa1862ca59e97f8f866c
# the hypothesis on the private exponent (the theoretical maximum is 0.292) delta = .28# this means that d < N^delta
# # Lattice (tweak those values) #
# you should tweak this (after a first run), (e.g. increment it until a solution is found) m = 4# size of the lattice (bigger the better/slower)
# you need to be a lattice master to tweak these t = int((1-2*delta) * m) # optimization from Herrmann and May X = 2*floor(N^delta) # this _might_ be too much Y = floor(N^(1/2)) # correct if p, q are ~ same size
# # Don't touch anything below #
# Problem put in equation P.<x,y> = PolynomialRing(ZZ) A = int((N+1)/2) pol = 1 + x * (A + y)
# # Find the solutions! #
# Checking bounds if debug: print("=== checking values ===") print("* delta:", delta) print("* delta < 0.292", delta < 0.292) print("* size of e:", int(log(e)/log(2))) print("* size of N:", int(log(N)/log(2))) print("* m:", m, ", t:", t)
defGCRT(mi, ai): # mi,ai分别表示模数和取模后的值,都为列表结构 curm, cura = mi[0], ai[0] for (m, a) in zip(mi[1:], ai[1:]): d = gmpy2.gcd(curm, m) c = a - cura assert (c % d == 0) #不成立则不存在解 K = c // d * gmpy2.invert(curm // d, m // d) cura += curm * K curm = curm * m // d cura %= curm return (cura % curm, curm) #(解,最小公倍数)
defgen_irreducable_poly(deg): whileTrue: out = R.random_element(degree=deg) if out.is_irreducible(): return out P = gen_irreducable_poly(ZZ.random_element(length, 2*length)) Q = gen_irreducable_poly(ZZ.random_element(length, 2*length))
e = 65537
N = P*Q S.<x> = R.quotient(N)
flag = 'xxxx' flag = list(bytearray(flag.encode())) m = S(flag) c = m^e
defrho(n): i = 1 whileTrue: a = getRandomRange(2, n) b = f(a, n) j = 1 whileTrue: p = GCD(abs(a - b), n) print('{} in {} circle'.format(j, i)) if p == n: break elif p > 1: return (p, n // p) else: a = f(a, n) b = f(f(b, n), n) j += 1 i += 1
defmain(): n = 2062899536811871554818178359324161185631864322612928428737135410318396234838612759353304630466467882907238599097155276236974469077407927587176395102072905755064272779705304103155044175760772870357960042973800466612294120431806053764425995115279842108284227580763784948966673592802930476849233889221985236020626654664840038198318033843640935727802767372332931755961464416884826343968074190784107977317020369409515252779597705798495979144688260140280406347997234735504377161004933444363855269475346955181189441066456092467816293921375731674289071178645028262851698651731976240122083422857066357348367076175249101149547 print(rho(n))
if __name__ == '__main__': main()
More
common prime RSA在g过小时,g也能轻易通过分解N-1来解出(rho等算法分解出的小因子尝试即可)
defgen_prime(nbits, gamma): g = 2 * getPrime(int(nbits * gamma)) whileTrue: a = getRandomNBitInteger(int((0.5 - gamma) * nbits - 1)) p = g * a + 1 if isPrime(p): b = getRandomNBitInteger(int((0.5 - gamma) * nbits - 1)) q = g * b + 1 whilenot isPrime(q) or GCD(a, b) != 1: b = getRandomNBitInteger(int((0.5 - gamma) * nbits - 1)) q = g * b + 1 return p, q
defgen_key(nbits, gamma): p, q = gen_prime(nbits, gamma) n = p * q lcm = (p * q) // GCD(p, q) e = getPrime(16) while GCD(e, lcm) != 1: e = getPrime(16) d = inverse(e, lcm) return (n, e), (p, q, d)
import decimal from pwn import * from Crypto.Util.number import long_to_bytes
deforacle(c): io = remote('111.198.29.45', '42484') io.recvuntil('You can input ciphertext(hexdecimal) now\n') c = hex(c)[2:] if len(c) & 1: c = '0' + c io.sendline(c) res = io.recvline(keepends=False) io.close() assert(res == b'odd'or res == b'even') return res == b'odd'
defpartial(c, e, n): nbits = n.bit_length() decimal.getcontext().prec = nbits low = decimal.Decimal(0) high = decimal.Decimal(n) for i in range(nbits): c = (c * pow(2, e, n)) % n ifnot oracle(c): high = (low + high) / 2 else: low = (low + high) / 2 print(i, '/', nbits) return int(high)
defmain(): #c = int(input("c = ")) #e = int(input("e = ")) #n = int(input("n = ")) e = 0x10001 n = 0x0b765daa79117afe1a77da7ff8122872bbcbddb322bb078fe0786dc40c9033fadd639adc48c3f2627fb7cb59bb0658707fe516967464439bdec2d6479fa3745f57c0a5ca255812f0884978b2a8aaeb750e0228cbe28a1e5a63bf0309b32a577eecea66f7610a9a4e720649129e9dc2115db9d4f34dc17f8b0806213c035e22f2c5054ae584b440def00afbccd458d020cae5fd1138be6507bc0b1a10da7e75def484c5fc1fcb13d11be691670cf38b487de9c4bde6c2c689be5adab08b486599b619a0790c0b2d70c9c461346966bcbae53c5007d0146fc520fa6e3106fbfc89905220778870a7119831c17f98628563ca020652d18d72203529a784ca73716db c = 0x4f377296a19b3a25078d614e1c92ff632d3e3ded772c4445b75e468a9405de05d15c77532964120ae11f8655b68a630607df0568a7439bc694486ae50b5c0c8507e5eecdea4654eeff3e75fb8396e505a36b0af40bd5011990663a7655b91c9e6ed2d770525e4698dec9455db17db38fa4b99b53438b9e09000187949327980ca903d0eef114afc42b771657ea5458a4cb399212e943d139b7ceb6d5721f546b75cd53d65e025f4df7eb8637152ecbb6725962c7f66b714556d754f41555c691a34a798515f1e2a69c129047cb29a9eef466c206a7f4dbc2cea1a46a39ad3349a7db56c1c997dc181b1afcb76fa1bbbf118a4ab5c515e274ab2250dba1872be0 m = partial(c, e, n) print(long_to_bytes(m))
import threading from gmpy2 import iroot from functools import reduce from Crypto.Util.number import * import time
factor_state = False
defpow_with_sqrt(a, c, b, n, mod):# (a+c*sqrt(b))^n states = [(a % mod, c % mod)] for i in range(int(math.log(n, 2))): new_state = ((pow(states[i][0], 2, mod) + b * pow(states[i][1], 2, mod)) % mod, (2 * states[i][0] * states[i][1]) % mod) states.append(new_state) n_bin = bin(n)[2:][::-1] res_x = 1 res_y = 0 for i in range(len(n_bin)): if n_bin[i] == '1': res_x, res_y = (res_x * states[i][0] + res_y * states[i][1] * b) % mod, (res_x * states[i][1] + res_y * states[i][0]) % mod return res_x, res_y
defwilliam_factor(n, index): start = time.clock() global factor_state A = getRandomRange(3, n) #m = 2 #next_pos = 1 m = 3000 next_pos = reduce(lambda x, y : x * y, [i + 1for i in range(m - 1)]) B = A**2 - 4 #res_x1, res_y1 = A, -1 #res_x2, res_y2 = A, 1 res_x1, res_y1 = pow_with_sqrt(A, -1, B, next_pos, n) res_x2, res_y2 = pow_with_sqrt(A, 1, B, next_pos, n) whileTrue: if factor_state == True: return print((index, m)) next_pos *= m #next_pos = m! C = inverse(pow(2, next_pos, n), n) res_x1, res_y1 = pow_with_sqrt(res_x1, res_y1, B, m, n) res_x2, res_y2 = pow_with_sqrt(res_x2, res_y2, B, m, n) res_x, res_y = (res_x1 + res_x2) % n, (res_y1 + res_y2) % n assert(iroot(B, 2)[1] == Falseand res_y != n) if iroot(B, 2)[1] == True: res_x = (res_x + res_y * iroot(B, 2)[0]) % n # Vi = C((A-sqrt(B))^(m!)+(A+sqrt(B))^(m!)) Vi = (C * res_x) % n p = GCD(Vi - 2, n) assert(p != n) #p=n说明lucas序列下标过大 if p != 1: factor_state = True print('p =', p) end = time.clock() print('cost {}s'.format(end - start)) return m += 1
defmain(): n = 7941371739956577280160664419383740967516918938781306610817149744988379280561359039016508679365806108722198157199058807892703837558280678711420411242914059658055366348123106473335186505617418956630780649894945233345985279471106888635177256011468979083320605103256178446993230320443790240285158260236926519042413378204298514714890725325831769281505530787739922007367026883959544239568886349070557272869042275528961483412544495589811933856131557221673534170105409 #n = 112729 threads = [] for i in range(3): t = threading.Thread(target=william_factor, args=(n, i)) threads.append(t) for t in threads: t.start() for t in threads: t.join()
if __name__ == '__main__': main()
More
关于William’s p+1 Algorithm的证明:
Lucas Functions:设$\alpha,\beta$是$x^{2}-Px+Q=0$的根,且有
prime = [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53,59,61,67,71,73,79,83,89,97,101,103,107,109,113,127,131,137,139,149,151,157,163,167,173,179,181,191,193,197,199,211,223,227,229,233,239,241,251,257,263,269,271,277,281,283,293,307,311,313,317,331,337,347,349,353,359,367,373,379,383,389,397,401,409,419,421,431,433,439,443,449,457,461,463,467,479,487,491,499,503,509,521,523,541,547,557,563,569,571,577,587,593,599,601,607,613,617,619,631,641,643,647,653,659,661,673,677,683,691,701,709,719,727,733,739,743,751,757,761,769,773,787,797,809,811,821,823,827,829,839,853,857,859,863,877,881,883,887,907,911,919,929,937,941,947,953,967,971,977,983,991,997]
defLucas_pow(P, R): A, B = P, 2 R = bin(R)[3:] for i in R: if int(i) == 1: A, B = (P * A**2 - A * B - P) % n, (A**2 - 2) % n else: A, B = (A**2 - 2) % n, (A * B - P) % n return gcd(A - 2, n)
defWilliams_p_1(): R = 1 B = iroot(n, 2)[0] B = log(B) for pi in prime: for i in range(B//log(pi)): R *= pi while1: P = random.randint(2, B) p = Lucas_pow(P, R) if p > 1and p < n: return p
defpow_in_Fp2(a, b, n, p):# (a+sqrt(b))^n in Fp^2 states = [(a % p, 1)] for i in range(int(math.log(n, 2))): new_state = ((pow(states[i][0], 2, p) + b * pow(states[i][1], 2, p)) % p, (2 * states[i][0] * states[i][1]) % p) states.append(new_state) n_bin = bin(n)[2:][::-1] res_x = 1 res_y = 0 for i in range(len(n_bin)): if n_bin[i] == '1': res_x, res_y = (res_x * states[i][0] + res_y * states[i][1] * b) % p, (res_x * states[i][1] + res_y * states[i][0]) % p return res_x, res_y
defsquare_root(a, p): assert(euler_judge(a, p) == True) if p % 4 == 3: b = pow(a, (p + 1) // 4, p) elif p % 8 == 5: c = pow(2 * a, (p - 5) // 8, p) i = (2 * a * c**2) % p b = (a * c * (i - 1)) % p else: t = getRandomRange(1, p) u = t**2 - a while euler_judge(u, p): t = getRandomRange(1, p) u = t**2 - a b, check = pow_in_Fp2(t, u, (p + 1) // 2, p) assert(check == 0) return b, -b % p