Stream Cipher - Many Time Pad
Theorem
流密钥循环使用
猜测密钥长度
Hamming Distance(二进制下两个等长字符串的比特位差异)
大小写英文字符两两的平均Hamming距离为2 ~ 3,而任意字符两两的平均Hamming距离为4
取合适的密钥长度上下界,进行分组计算汉明距离
将二元组(key_length, distance)按distance升序排列,取前五组验证即可
逐字节破解密钥
在猜测的密钥长度基础上,分割Cipher(用同一密钥字节加密的密文归入同组)
字频分析
遍历range(0xff),和标准频率表(含空格和字母)内积最大的即猜测为正确密钥字节
因为不正确密钥字节下也可能内积很大,所以进行如下filter:
decode(‘ascii’)出错 => return 0
cipher分组里为空格或字母的字符总数 < len(cipher_fragment) // 1.5 => return 0
爆破空格
基于空格和小写字母异或结果为对应大写字母,和大写字母异或结果为对应小写字母这一特性
对同一分组的cipher进行两两异或(相当于plain两两异或),记录每个字符与其他所有字符异或结果落在落在大小写字母和0x00上的次数,即可认为最大次数对应的字符位置上的明文为空格
exp
1 | import string |
LFSR - Basis
Theorem
单个lfsr且已知抽头序列的情况下,只要有任意n个比特的流信息,即可轻易恢复完整流
等价于解n元1次方程(18年国赛streamgame)
exp
1 | # In[26] |
LFSR - Correlation Attack
Theorem
实际使用的lfsr往往是多个lfsr并行,并通过代数运算F来获得密钥流
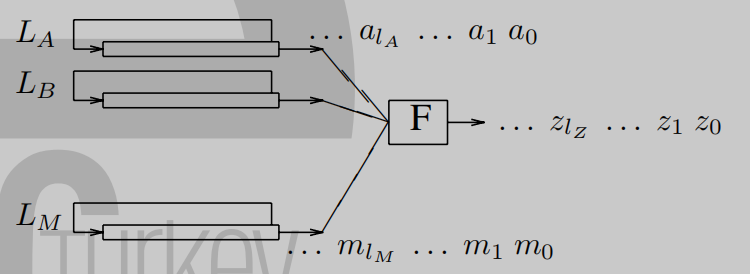
列出代数运算F的真值表,即可得到相关系数$p_{1},…,p_{n}$
一般认为在$p_{i}\geq 0.6$时,能使用相关攻击对第i个lfsr的密钥流实现恢复($p_{i}=0.75$时效果较好)
相关攻击使得复杂度从$\prod$优化为$\sum$,余下相关系数趋于0.5的lfsr采用暴力枚举即可
exp
1 | import threading |
1 | (0.75, 0.5, 0.75) |
More
exp对应的是强网杯streamgame3,在pypy3下大约七八分钟能出答案,但python3估计就有点儿慢了-.-
网上现在传的版本大多也都只是相关攻击,顶多在多线程上进行部分优化
快速相关攻击的A算法原理理解很容易,但我编写脚本测试后发现出不来…暂时搁置
安全客上有一篇讲LFSR相关攻击的文章,分别用了开普敦大学的轮子和z3约束来进行求解,链接如下
https://www.anquanke.com/post/id/184828
LFSR - Known Plain Attack
Theorem
LFSR的KPA问题(已知明文长度要大等于两倍的LFSR级数n)
- 对LFSR级数n进行range(2, len(stream) // 2)上的爆破(stream是已知明文段)
- 因为$len(stream)//2\geq n$,所以每个猜测级数i下均对应至少i个i元线性方程(系数矩阵秩<i情况一般不考虑)
- LFSR的下一位只受当前n位和抽头序列影响,因此得到n个GF(2)上形如$\sum_{i=1}^{n}p_{i}$, if stream[i]==1的线性方程,于是抽头序列$\\{p_{i}\\}$获知,恢复全部明文并校验即可
exp
1 | from z3 import * |
More
exp对应2020i春秋公益赛的一道lfsr-kpa(已知png文件头,与cipher异或即可将问题转化为lfsr-kpa问题)
lfsr-kpa可以不局限于开头,密钥流中任意段已知2n个bit均可进行抽头序列的猜测(lfsr在已知n个连续比特和抽头序列的情况下一定能恢复完整密钥流)